This paper was posted a few weeks ago: Moderation in instant runoff voting
In this work, we prove that IRV has a moderating effect relative to traditional plurality voting in a specific sense, developed in a 1-dimensional Euclidean model of voter preferences. Our results show that as long as voters are symmetrically distributed and not too concentrated at the extremes, IRV will not elect a candidate that is beyond a certain threshold in the tails of the distribution, while plurality can.
This is certainly true, as they frame it. There is an extreme region of the political spectrum where FPTP will elect candidates that IRV doesn't:
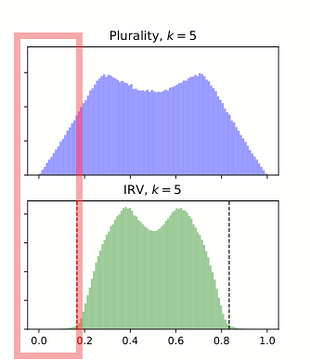
But it's a bit weird of a claim to make, since IRV is still pretty broad, and has that valley of anti-moderateness in the middle, and other voting systems do much better. They acknowledge this to some extent, saying they focus on IRV because it's the only system with momentum:
First, we are not trying to characterize all possible voting systems that have a moderating effect under our formal definition, and if our goal were simply to design a voting system that has a moderating effect, there are many additional systems not in wide use that exhibit this property (any Condorcet method, for instance, or the Coombs rule [7, 22]). Our interest, instead, is in the fact that IRV and plurality are both used extensively in practice, and that they differ in this key property: IRV has a moderating effect and plurality does not.
Finally, as we noted earlier, there are voting systems that always select the most moderate candidate with symmetric 1-Euclidean voters. This is true for any system that satisfies the Condorcet criterion, selecting the Condorcet winner whenever one exists (this holds for the Copeland, Black, and Dodgson methods [3, 37]); it is also true for some other voting systems that do not in general satisfy the Condorcet criterion, like the Coombs rule [7, 22]. There are a variety of practical and historical reasons why these methods are not widely used for political elections. For instance, Dodgson’s method is NP-hard to compute and the Coombs rule is very sensitive to incomplete ballots, which are common in practice. As we are motivated by ongoing debates about IRV and plurality, our attention has been restricted to these voting methods. However, a broader understanding of moderating effects of voting systems would be valuable. There has been some theoretical work on moderating effects of score-based voting systems (like Borda count and approval voting) with strategic voters and candidates [11]. However, it is an open question (with some computational evidence to support it [5]) whether other voting systems like Borda count exert a moderating effect in the setting we study, with fixed voter and candidate distributions.
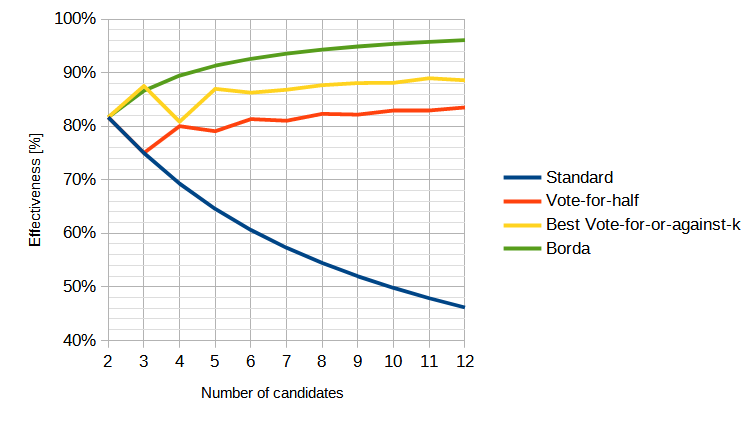
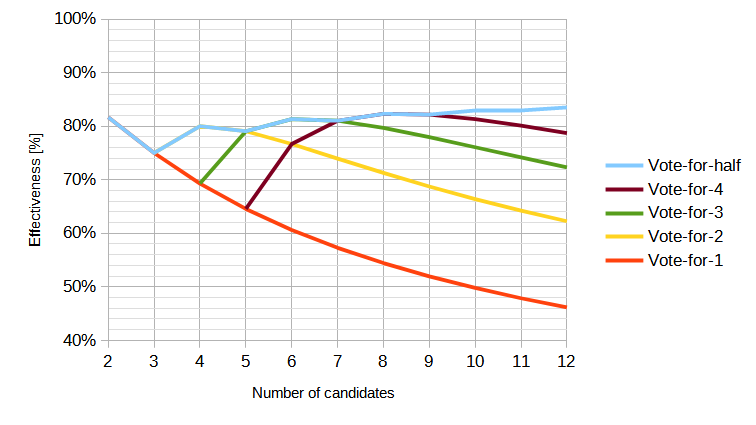
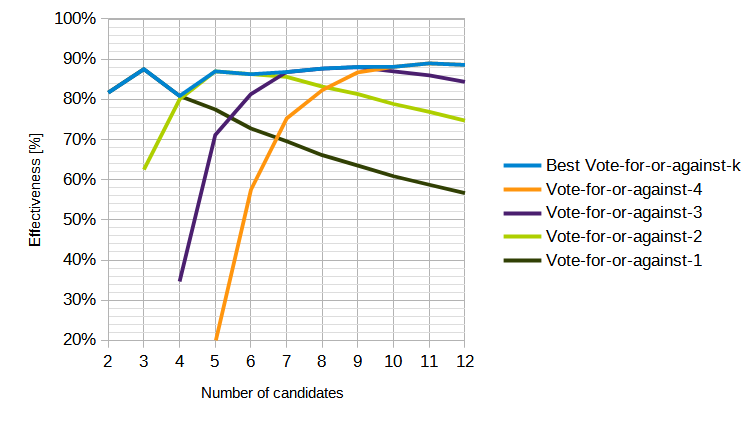
I've previously done similar simulations of other systems (though with a normal distribution of voters and candidates instead of a uniform distribution, which I think is more realistic) :
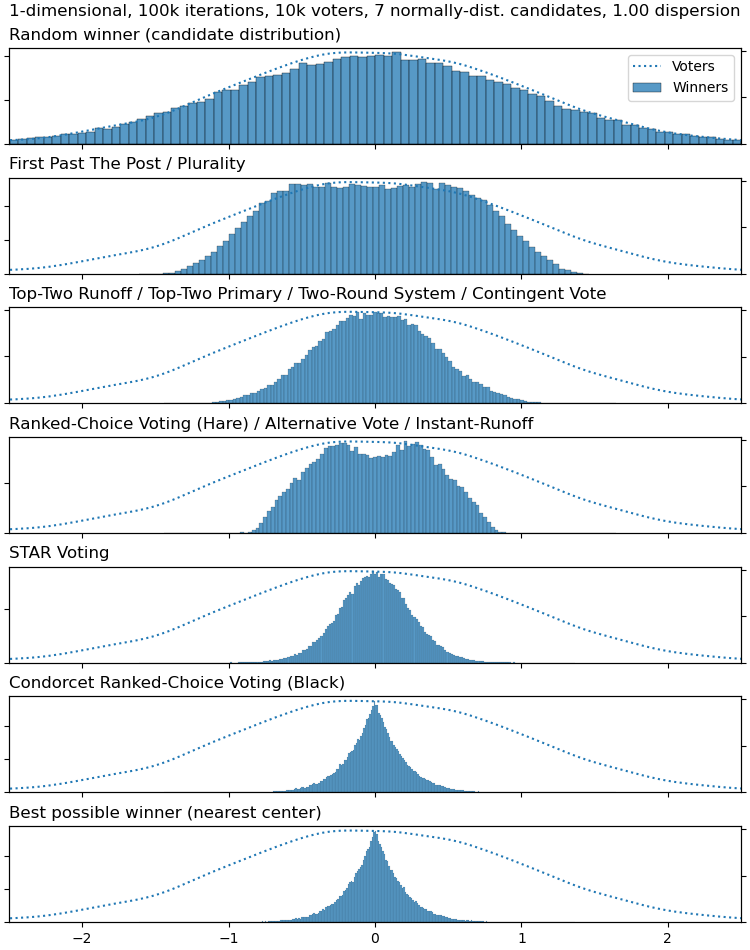
I was surprised by how similar the "first-choice only" systems behave when the candidates are clustered more tightly than the voters:
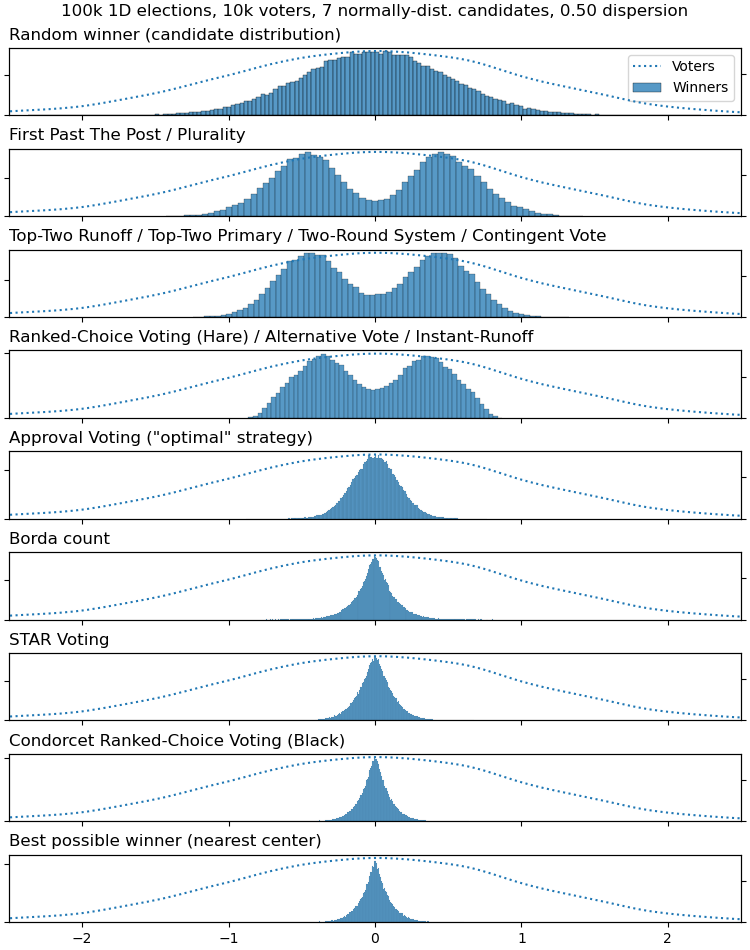
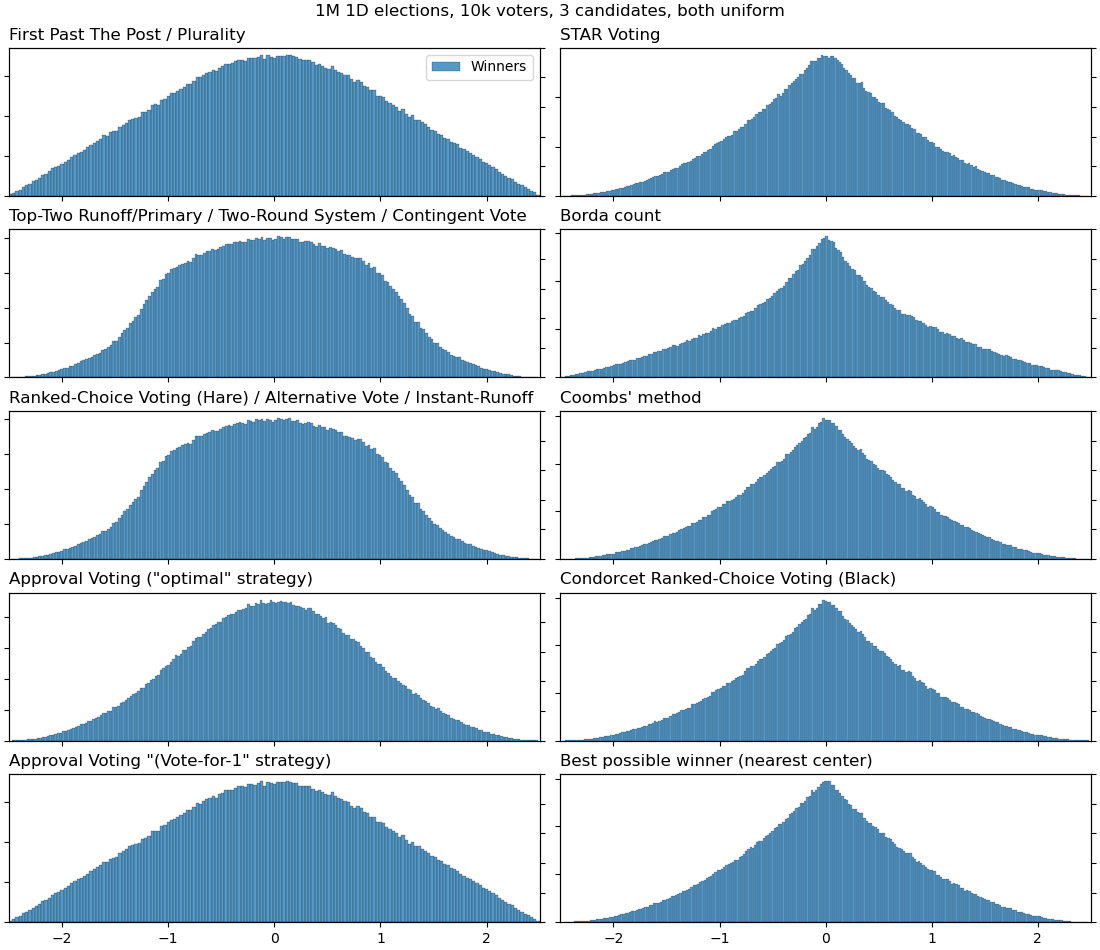
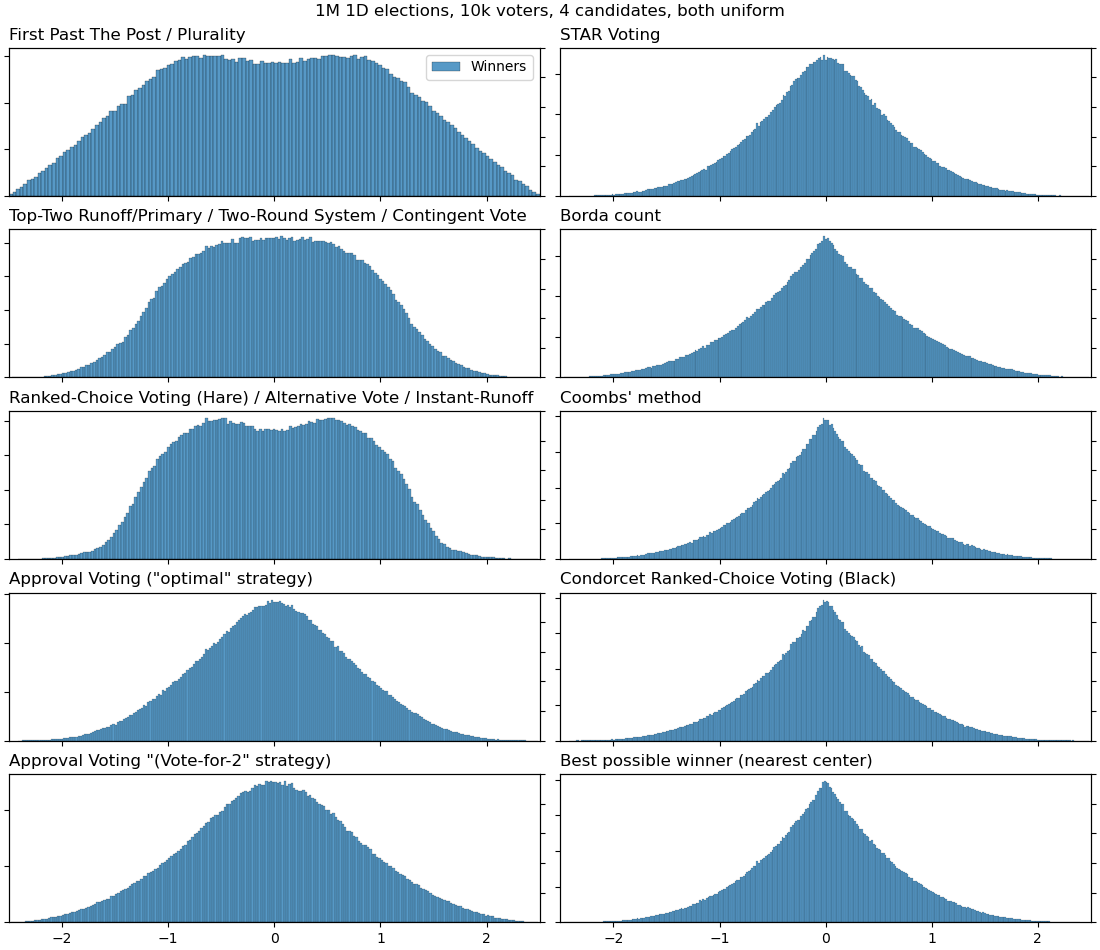
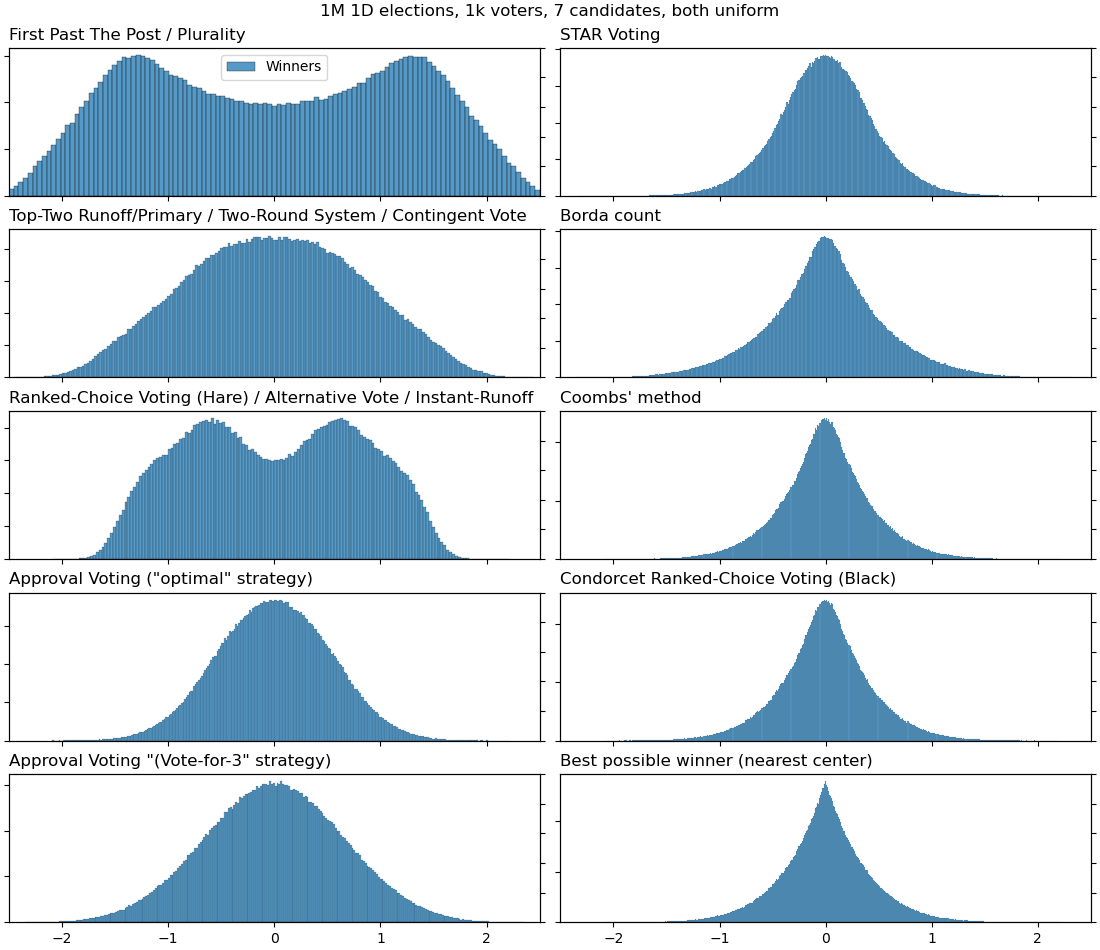
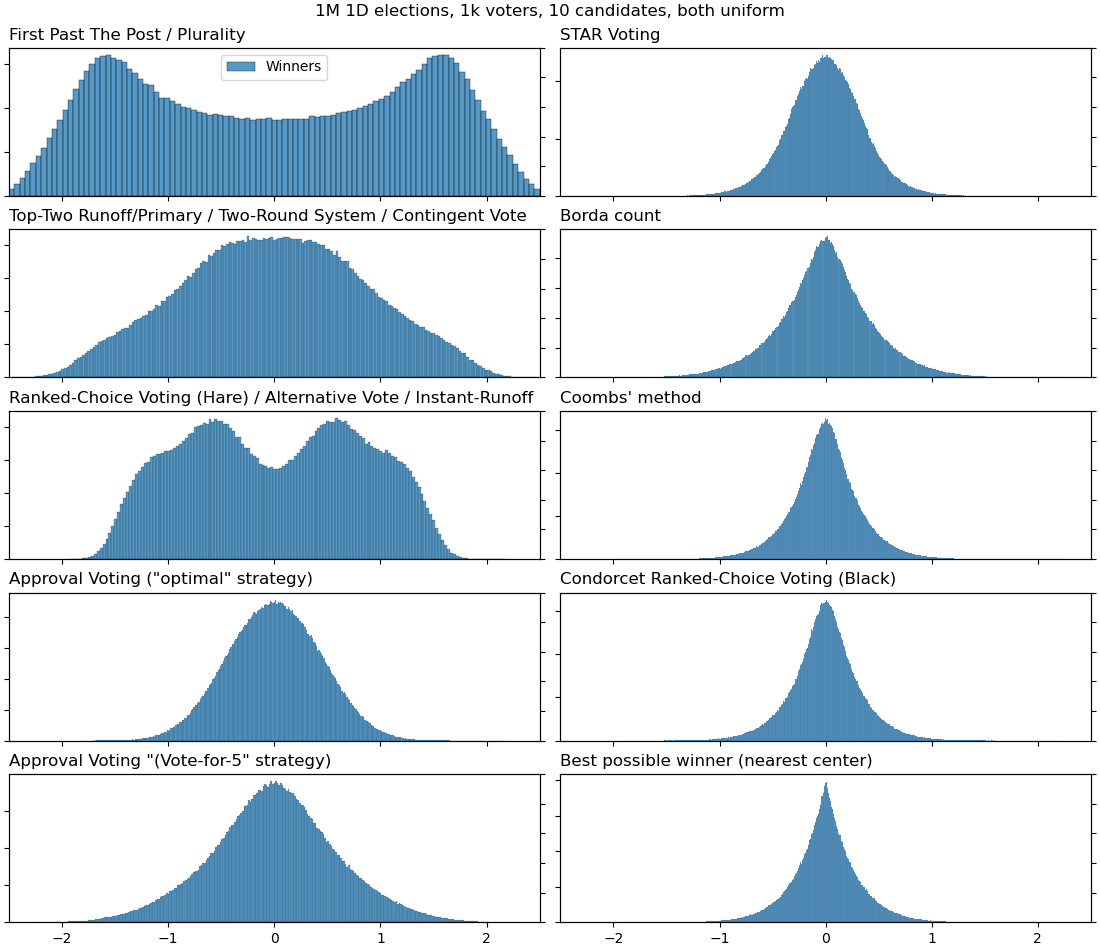
Anyway, I've tried to reproduce the graphs of the paper (with uniformly-distributed voters and candidates) but with some additional voting systems for comparison:
3 candidates:
4 candidates:
5 candidates:
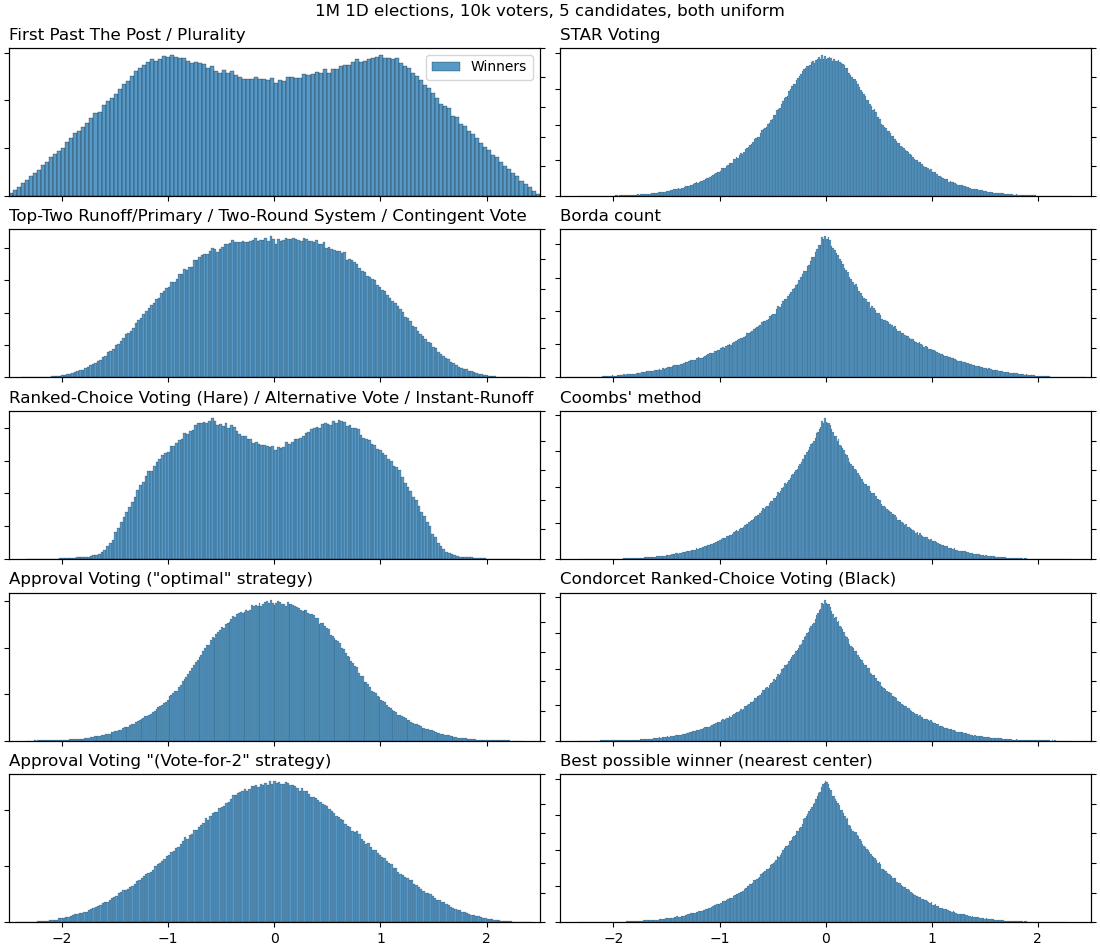
7 candidates:
10 candidates:
(Approval "optimal" strategy is as described in Merrill 1984: Each voter approves of all candidates they like more than average. "Vote-for-n" strategy is where every voter approves of their n most-favored candidates, from Weber 1978. STAR strategy is honest, proportional to max and min. Ranked ballot systems use honest strategy.)