votevote.page is live
-
@culi For runoff methods, a step beyond what you have labelled fab_irv might be either the Nanson or Baldwin methods.
Score Sorted Margins[100]; STAR[90]; Score[81]; Approval[59]; IRV[18]; FPTP[0]
-
@marylander Thanks! Both of those methods are actually on my todo list haha. The full list of planned methods is constantly growing haha
One fun thing I'd like to do with this is create a "meta" voting system. In which people score the candidates as they please and then also answer a second question which is "Which voting method would you prefer your vote be counted in?"
Say 5% of people voted for First Past the Post, 25% vote for River, 30% vote for Approval, 35% vote for IRV, and 5% vote for Borda. Then the winner of FPTP gets 0.05 points, the winner of River gets 0.25 points, the winner of Approval get 0.3 points, etc.
I think the strategic voting tactics could get really fun with this one

(Obviously this is not a serious voting method and the only application of it I can see is to get a group of voting theory nerds to shut up and vote)
-
@culi Am I missing something or are the methods Score, Approval, STAR and STLR missing?
-
@keith-edmonds Sorry, where did you see something about those methods?
In my original post I said that the original prototype had 26 methods (including all those you mentioned), but the new version only implemented 10 so far. Actually today I just released a new version that has 15 more including Score, Approval, and some really fun ones. So we're up to a total of 25 methods now. Check it out:
In the next update I hope to have added some of those hybrid systems (3-2-1, STAR, and more). I might put off STLR tho. The priority for the next update is to create a matrix visualization for methods like Copeland that do pairwise comparisons. I think those make a lot more sense than bars.
Anyways, hope you enjoy the new update. Would love any feedback. More updates to come soon hopefully
-
@culi I just think that the priority sequence you have chosen seems odd. Approval, STAR and IRV are the systems which are popular so why not start with them
-
@keith-edmonds Sorry, but I don't really understand this criticism. The initial voting system blocks were Plurality (fptp the default) and Runoff (IRV the default). IMO these are the two most popular voting systems. I'm not sure if you've read the "explanation" texts, but I feel like there's a very clear and natural progression for all of them. I introduced the 2 most popular methods and then slight variations on them. Yes "coombs" is much less known than "approval" but if someone has already put in the effort to understand IRV, it's really easy to say "coombs is the same thing but instead you drop the most hated candidate each round" than to introduce an entirely new voting system. After FPTP and IRV, I wrote contingency (along with some of its variations) which I'd also say is extremely popular given that the primary/general system is widely used and its an abstraction of that so it's easy to explain.
The whole pattern here is:
- introduce some popular voting system
- show them some ways you can modify it and see how that'd change the outcome
- introduce another voting system (and maybe explain what it does that the previous block didn't)
But anyways, if you MUST know why I really wrote them in the way that I did, it's actually because I've done this project twice. The first time (what I call the prototype) I did it pretty much exactly as you were saying where I started off writing only the most well known voting methods first. It eventually got to the point of 26 voting methods. One major thing I realized is that if I cached the results of other methods, I could make some massive efficiency gains. E.g. no need to calculate the Borda score twice for STAR and Borda when I could reuse the results of the calculation
So the central realization behind this new project is that I could make a really efficient "SuperSystem" that entangles all of these methods at once and calculates all of these results in one go and avoids repeat calculations as much as possible. Organizing the methods into "blocks" makes sense not just as an educational toy, but for the sake of developing this SuperSystem in a way that similar blocks of logic are grouped together.
Anyways, other than STAR, I feel like the latest update includes all the "canonical" popular voting methods so I hope your concerns are alleviated. I'd definitely like to implement STAR and some more Condorcet methods soon though
-
I doubt anyone's really following along, but just wanted to say this project isn't dead. I got a new job so I've been spending most of my free time learning the tech stack there, but I did recently release a much needed styling update:
Still have a lot I wanna do with it eventually. Some ideas include:
- make-your-own voting system: e.g. give a custom vector to make a positional system or define a cutoff and threshold method to create a runoff system. Also can automatically compare with existing system to find which other voting system is most similar
- comparisons & analysis: e.g. which systems correlate most strongly with other systems?
- host actual votes: just what it sounds like. you'd also be able to see how the outcome would've differed if you'd chosen an alternative system
- manipulation game: try to change the outcome by either removing a candidate, adding spoiler candidates, changing your vote, changing the voting system used, etc
But the priority right now is just to optimize the existing systems (and then I can finally add more complex condorcet methods)
I also genuinely want this to be a really accessible tool so I'm learning how to use a screen reader and I'm also exploring progressive web apps (PWAs) so that this can be run offline
I'll make another thread once I have a more substantial update
PS I definitely tend to fall victim to feature creep with my project, but I hope to be able to stick to the core functionality long enough for an over-the-top roadmap to not hinder the project. I think I can build it with future features in mind without sacrificing too much. Also really hope to open this open-source project up to external contributions once the codebase is sufficiently cleaned up
-
@culi Was just playing around with it and a bit confused on one thing: FPTP and Veto seem to produce almost exactly opposite results. I understand that the methods are opposite in a sense, but that shouldn't mean that the most common first choice in one is going to be the most common last choice in the other. I suspect that you are tallying them wrong.
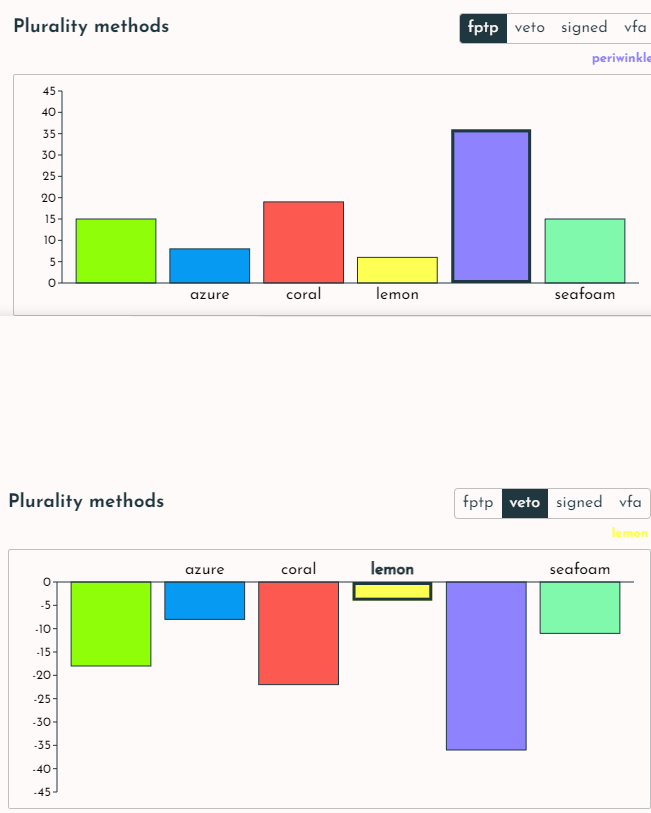
The same issue applies to VFA (for and against). Candidates that get lots of positive votes seem to also get a similar number of negative votes. That seems unlikely.
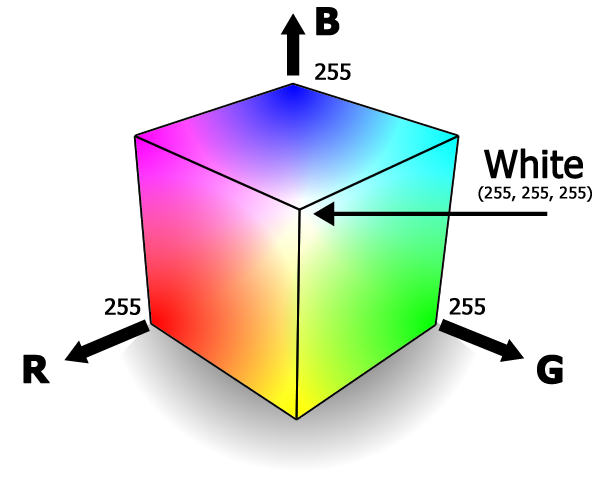
Regarding colors: I think you should stick with RGB rather than mixing HLS into your distance formular. RGB treats it spacially, so a middle gray candidate should approximate the median (right in the center of the RGB cube). I'd think that's what you'd want. HLS is weird in that hue is cyclical, and it is going to see colors like gray with a slight tinge of yellow and gray with a slight tinge of blue as being pretty far apart, since their hues are so different (even if they are very close to each other in any color space), while pure yellow and pure blue are going to be very close in saturation even though they are polar opposites in any color space.
I tried creating a gray candidate, and they performed very poorly with all methods, even though you'd think they'd do well on most methods (being in the middle of color space / ideological space).
On to a bigger issue: are you assuming the candidates are voting entirely naively? For instance, in FPTP, do they simply pick their favorite candidate, rather than factoring in how likely they think it is for each candidate to be a front runner?
-
@rob Hey rob thanks so much for the detailed feedback!
FPTP and Veto seem to produce almost exactly opposite results. [...] I suspect that you are tallying them wrong.
Thanks! You can actually confirm this yourself. You can hover over each voter on the left hand side and it'll tell you their preference scores for each candidate:
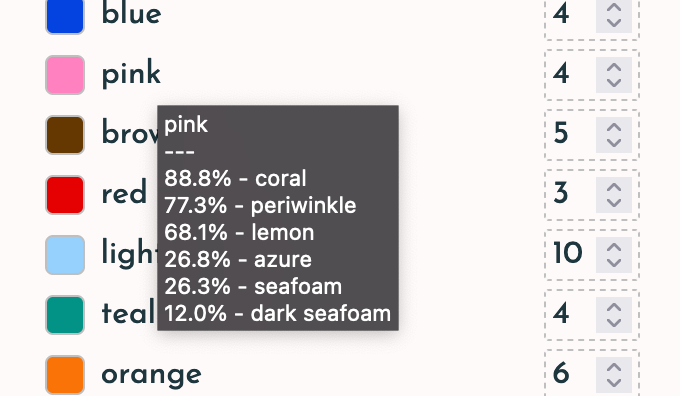
I'll write some unit tests to check if there is a flaw in the calculation, but I think what's most likely happening is that your spoiler candidate ends up making lemon very unlikely to be the most liked and also very unlikely to be the most hated
The same issue applies to VFA (for and against). Candidates that get lots of positive votes seem to also get a similar number of negative votes. That seems unlikely.
Will add tests for this as well.
Regarding colors: I think you should stick with RGB rather than mixing HLS into your distance formular.
I have a solution for this in the works. In the original prototype you are able to switch between RGB and HSL scoring systems. In a future update I'll add this ability back in as it should be pretty simple to do so. I was gonna put it off for a bit, but now that I've some feedback on it I'll prioritize it for the next release
") The only reason I've really been putting it off is because I wanted to make it a bit fancier than just RGB or HSL. Besides the idea of including more complex color spaces, I wanted to let users checkmark which components they wanted (i.e. some weird R+G+B+H hybrid). And yes I'm well aware of how tricky it can be to calculate distance for a component that is cyclic. I spent a lot of time trying to get that right haha
The only reason I've really been putting it off is because I wanted to make it a bit fancier than just RGB or HSL. Besides the idea of including more complex color spaces, I wanted to let users checkmark which components they wanted (i.e. some weird R+G+B+H hybrid). And yes I'm well aware of how tricky it can be to calculate distance for a component that is cyclic. I spent a lot of time trying to get that right hahaI tried creating a gray candidate, and they performed very poorly with all methods, even though you'd think they'd do well on most methods
The weird color distance formula was actually created specifically to prevent this tbh. The formula ended up weird and if you want a killer candidate try adding "leather" instead of some gray. The reason for this actually has a lot more to do with bias in the data source itself. The color names are taken from the amazing XKCD color survey in which ~140,000 people were prompted random RGB values and asked to name them. XKCD then did some averaging to map color names on to specific points. The colors here are the 954 most popular color names given. It just so happens that people seem to have a lot more names for shades or red/brown colors than most other parts of the RGB color space. I figured if the data source is already biased towards human I might as well use my own human bias in the scoring system to try to concoct something that seems fair to me.
However I agree that the best course of action is to leave this option in the hands of the user
On to a bigger issue: are you assuming the candidates are voting entirely naively?
Yup! This is supposed to be an exploration of the ways to count votes itself and not at all model real life elections. I don't really make any attempts to model voter behavior. But I'll add this to the list of future toggleable options the user can play with
Last note: The XKCD color data is just one data source. The original prototype used a different set of colors that I hand crafted. However, the way that the election calculations work is that each ballot just needs to have an assigned score for each candidate between 0 and 1. This is abstract enough that it should be very trivial to add, for example, different cities in Tennessee voting for which capital to have. This can easily be expanded to more cities than the 4 typically used as examples. The exciting part is that it should also be really simple to add arbitrary custom data as well. So anyone with a set of candidates and a set of ballots (again, ballots are just a mapping of each candidate to 0..1) can model an arbitrary election across all of these different methods. I guess this probably won't really be that useful until I add the ability to toggle more complex voter behavior however though
-
Upon further testing of veto and vfa, I still don't see much unexpected behavior. I think it might just be biases in the selected colors. The default candidates span the color hue pretty decently but this is very much an unlikely (though preferable) scenario to happen in the real world. I'll definitely still write those unit tests, but lemme know if you try it with different sets of candidates/voters and are still convinced there's weirdness
Also if you hover over the bars for a second you'll also see the specific score:
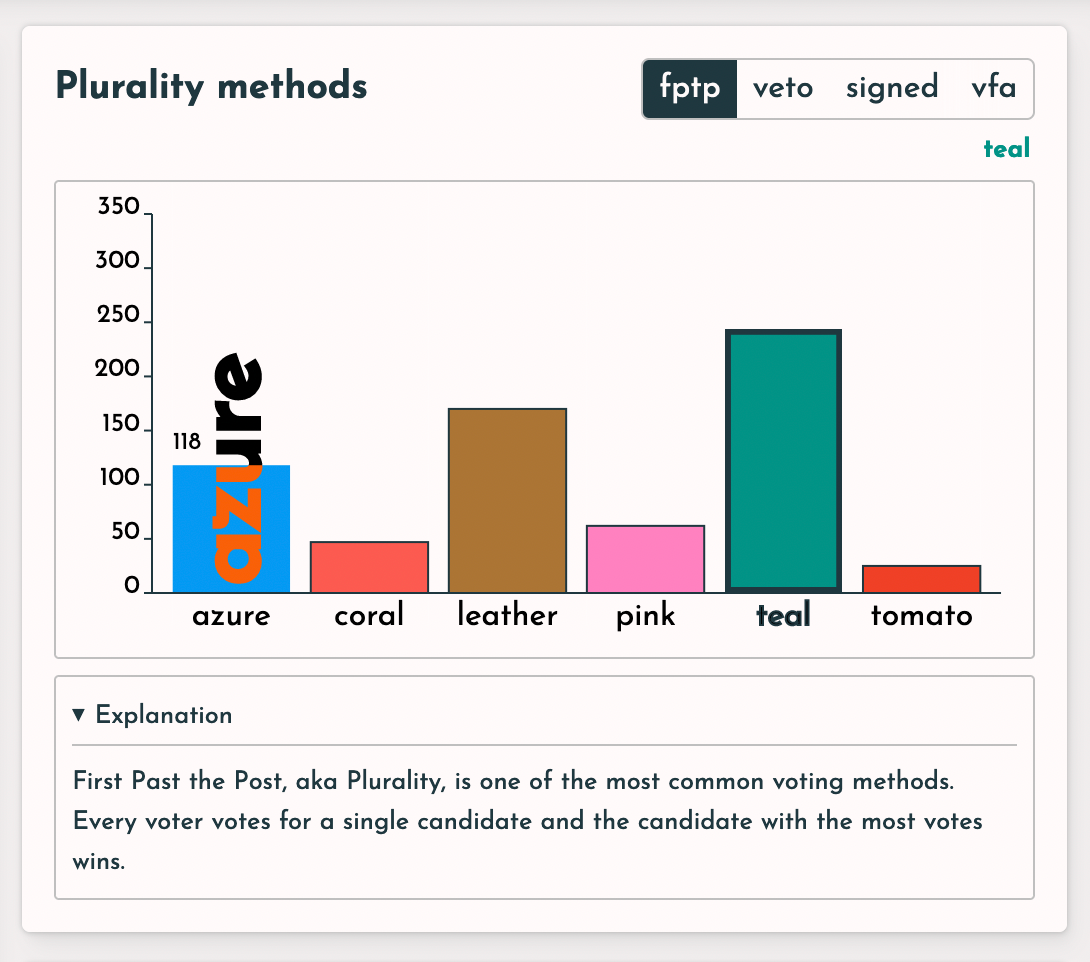
You can use this to quickly check that the fptp score + veto score = vfa score (it does indeed in my quick testing)
-
This is a cool video about computer color blending: https://www.youtube.com/watch?v=LKnqECcg6Gw
I'm not sure if it applies to the problems you're trying to solve with color distance. It's just generally related.
-
@paretoman Thanks for sharing. I think I've actually seen this same video before haha. I have a separate side project where I'm basically trying to recreate Bjorn Ottosson's color picker across multiple colorspaces:
https://bottosson.github.io/misc/colorpicker/
I don't really have anything original to add to this besides support for even more colorspaces. There's also some cool new CSS proposals coming in that will allow us to more easily work with some of these advanced color spaces so I'm eagerly awaiting browser adoption of those haha.
Definitely a space I'm keeping an eye on and have spent a lot of time thinking about. Hopefully that functionality will be integrated into VoteVote soon enough too
-
@paretoman Just rewatched the video. Yup my calculations do already use the geometric mean instead of the euclidean mean haha
-
PS you can preview the upcoming versions here: https://dev--votevote.netlify.app/
This week's been crazy at work so I probably won't be able to implement the color space changes until next weekend, but I have some other exciting updates already in
-
@culi The OKLrCH is interesting. It seems to give the least amount of banding when cycling through hues, at least in my eyes. I would think it would be really good for measuring distance. Well, with one transformation. I would use the hue (H) as a polar angle in cylindrical coordinates and C as the radius. Then convert to cartesian and measure distance. I don't know how I would actually implement this, but it's an idea
... I guess color space is like a double cone with extra pointy parts. I wonder how different this double cone would be from the RGB cube on its diagonal.
-
Regarding the video about how RGB blending is wrong due to gamma... that's true, although I suspect of minor importance in this scenario. But you could certainly do the conversion prior to comparing colors for proximity.
For your purposes, though, the gamma issue is pretty minor importance. If you are doing graphics stuff such as a paint program, much more so. The important thing here is to have it communicate to people who want to mostly think about voting theory, not color theory. (I say this as someone who has spent far more time working with and thinking about color theory than voting theory)
Whether or not you account for gamma, it is still RGB, though, and I think that's rather important. Other systems tend to have degenerate cases, as black white and gray in HSV. Hue is indeterminate for black, for instance, but near blacks would have a hue. So #000001 and #010000 both appear as black on most monitors, but have very different hues meaning they are treated as not-particularly-close colors. The significance of hue should be reduced as the saturation is reduced.... and that is true for RGB systems.
If you want to get even better, you can account for the fact that certain RGB colors (whether or not you've done the above d-gamma-ing) appear lighter than others even if their RGB sum is equal. Pure blue (#0000ff) is much darker-appearing than pure green (#00ff00), at least on monitors. (less so if printed with an ink jet). So you could distort the cube to account for that, like how the Munsell color model is distorted to put yellow at a higher value than blue.
Notice that in Munsell, the physical distance in the color solid is a good indicator of similarity of colors. However, the way Munsell numerically represents the colors (which is HSV, but not the simplified form used in most computer representations), would not be a good way to determine similarity, since it amplifies the importance of hue with low saturation colors.
It's great to allow users to have options, but for the vast majority of the users that don't spend a lot of time thinking about color theory, try to go with what is most intuitive: if colors appear similar, treat them as similar.
You spoke of color names, and that is a different issue. Personally I wouldn't use any names, or stick with simple ones (red, yellow, green etc) rather than expecting people know what is meant by "seafoam". I go to the beach often enough to know what the color of seafoam is, and it ain't that.

Yup! This is supposed to be an exploration of the ways to count votes itself and not at all model real life elections
Sure but strategy is sort of at the heart of all this stuff. You can simplify it, as I did with my simulators, but ignoring it altogether, seems quite misleading to me.
-
@rob The color names are based on XKCD's average from their survey of thousands of people. I'd say the results are, by design, much closer to how people map color names to colors than what some paint company decides
-
@culi Maybe true but I wouldn't rely on names at all, especially if you are using them in ways that go beyond simple visual. (i.e. "distance" between colors)
-
@rob Fair, but I still don't see why it's an issue. You can remove/add whatever candidates and/or voters you'd like. If you want to limit yourself to red/green/blue/other basic colors you totally can!
Anyways all these concerns should be resolved once I have it set up so anyone can add their own custom dataset
-
@culi said in votevote.page is live:
If you want to limit yourself to red/green/blue/other basic colors you totally can!
Gotcha. To be clear, I wasn't suggesting limiting to basic colors like that because that defeats the whole purpose. My suggestion would be pick the colors purely visually from a palette (a small 8x8 palette for 64 colors would be perfect), or using a color picker. If you use a color picker and it shows the RGB values that are used in the proximity calculations (preferably with gamma applied so it is more realistic per the linked video), people will know what 'color proximity' actually means, so I'd consider that a huge plus.
Expecting people to set up a custom dataset is fine, if it's that kind of app. If you want to have something that quickly communicates a concept though, not the approach I'd use.
Obviously it's your app and you can handle it as you want. I actually love the idea of using colorspace to represent ideological space, BTW.
-
Moved from Research and Projects by
 SaraWolk
SaraWolk